Analyzing Object Detection Dataset
In this tutorial, we will analyze an object detection dataset with bounding boxes and identify potential issues. We will cover the process of loading the annotations, visualizing bounding boxes, and finding objects that are possibly mislabeled or not useful for training (tiny, blurry, etc.).
When analyzing an object bounding box dataset, it is often useful to start with an image level analysis, to uncover low hanging fruits such as broken images and and duplicates. More on that in our Analyzing Image Classification tutorial.
In this tutorial we will analyze the image at the bounding box level.
Setting Up
You can follow along this tutorial by running this notebook on Google Colab
First, install fastdup with:
pip install fastdupAnd verify the installation.
import fastdup
fastdup.__version__This tutorial runs on version 0.906.
Download Dataset
We will be using the coco minitrain dataset for this tutorial.
coco-minitrainis a curated mini training set (25K images ≈ 20% of train2017) from the original COCO dataset.
Let's download the images and .csv annotations of the coco-minitrain dataset.
# Download images from mini-coco
!gdown --fuzzy https://drive.google.com/file/d/1iSXVTlkV1_DhdYpVDqsjlT4NJFQ7OkyK/view
!unzip coco_minitrain_25k.zip
# Download csv annotations
!cd coco_minitrain_25k/annotations && gdown --fuzzy https://drive.google.com/file/d/1i12p23cXlqp1QrXjAD_vu467r4q67Mq9/viewLoad annotations
We will use a simple converter to convert the COCO format JSON annotation file into the fastdup annotation dataframe. This converter is applicable to any dataset which uses COCO format.
import fastdup
import pandas as pd
coco_csv = 'coco_minitrain_25k/annotations/coco_minitrain2017.csv'
coco_annotations = pd.read_csv(coco_csv, header=None, names=['filename', 'col_x', 'row_y',
'width', 'height', 'label', 'ext'])
coco_annotations['split'] = 'train' # Only train files were loaded
coco_annotations = coco_annotations.drop_duplicates()coco_annotations.head(3)| img_filename | bbox_x | bbox_y | bbox_w | bbox_h | label | ext | split | |
|---|---|---|---|---|---|---|---|---|
| 0 | 000000131075.jpg | 20 | 55 | 313 | 326 | tv | 0 | train |
| 1 | 000000131075.jpg | 176 | 381 | 286 | 136 | laptop | 0 | train |
| 2 | 000000131075.jpg | 369 | 361 | 72 | 73 | laptop | 0 | train |
Run fastdup
image_dir = 'coco_minitrain_25k/images/train2017/' # Train data only
work_dir = 'fastdup_coco_25k'
fd = fastdup.create(work_dir, image_dir)
fd.run(annotations=coco_annotations, overwrite=True)FastDup Software, (C) copyright 2022 Dr. Amir Alush and Dr. Danny Bickson.
2023-02-26 11:34:40 [WARNING] Warning: test_dir and input_dir should not point to the same directory
2023-02-26 11:34:40 [INFO] Going to loop over dir /var/folders/27/6tpv2d5j2yd9rtg1ml23f5h40000gn/T/tmpxnmh4kii.csv
2023-02-26 11:34:40 [INFO] Found total 183546 images to run on
[■■■■ ] 7% Estimated: 5 Minutes 0 Features
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000402248.jpg. Please check bounding box file 14 241 3 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000141426.jpg. Please check bounding box file 106 224 2 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000564557.jpg. Please check bounding box file 30 271 5 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000183338.jpg. Please check bounding box file 241 287 3 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000088835.jpg. Please check bounding box file 292 200 3 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000168890.jpg. Please check bounding box file 7 95 1 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000171360.jpg. Please check bounding box file 339 181 8 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000256896.jpg. Please check bounding box file 210 350 3 0
Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000389655.jpg. Please check bounding box file 372 438 3 0
2023-02-26 11:39:33 [ERROR] Error: found invalid bounding box for image /Users/amirm/vl_data/coco_minitrain_25k/images/train2017/000000389655.jpg. Please check bounding box file 372 438 3 0
2023-02-26 11:39:42 [INFO] Found total 183546 images to run onated: 0 Minutes 0 Features
2023-02-26 11:42:49 [INFO] 186133) Finished write_index() NN model
2023-02-26 11:42:49 [INFO] Stored nn model index file /Users/amirm/vl_workdir/coco_minitrain_25k/tutorial_bboxes/nnf.index
2023-02-26 11:43:18 [INFO] Total time took 517522 ms
2023-02-26 11:43:18 [INFO] Found a total of 163 fully identical images (d>0.990), which are 0.03 %
2023-02-26 11:43:18 [INFO] Found a total of 5895 nearly identical images(d>0.980), which are 1.07 %
2023-02-26 11:43:18 [INFO] Found a total of 93110 above threshold images (d>0.900), which are 16.91 %
2023-02-26 11:43:18 [INFO] Found a total of 16495 outlier images (d<0.050), which are 3.00 %
2023-02-26 11:43:18 [INFO] Min distance found 0.483 max distance 1.000
2023-02-26 11:43:18 [INFO] Running connected components for ccthreshold 0.960000
########################################################################################
Dataset Analysis Summary:
Dataset contains 183546 images
Valid images are 89.87% (164,954) of the data, invalid are 10.13% (18,592) of the data
For a detailed analysis, use `.invalids()`.
Similarity: 3.96% (7,261) belong to 72 similarity clusters (components).
96.04% (176,285) images do not belong to any similarity cluster.
Largest cluster has 674 (0.37%) images.
For a detailed analysis, use `.connected_components()`
(similarity threshold used is 0.9, connected component threshold used is 0.96).
Outliers: 5.75% (10,553) of images are possible outliers, and fall in the bottom 5.00% of similarity values.
For a detailed list of outliers, use `.outliers(data=True)`.Get class statistics
fd.annotations()['label'].value_counts()person 50336
chair 7870
car 7703
bottle 4330
cup 4154
...
toothbrush 309
bear 296
parking meter 183
toaster 46
hair drier 40
Name: label, Length: 80, dtype: int64Class distribution
The dataset contains 25k images and 183k objects, an average of 7.3 objects per image.
Interestingly, we see a highly unbalanced class distribution, where all 80 coco classes are present here, but there is a strong balance towards the person class, that accounts for over 56k instances (30.6%). Car and Chair classes also contain over 8k instances each, while at the bottom of the list the toaster and hair drier classes contain as few as 40 instances.
Using Plotly we get a useful interactive histogram.
import plotly.express as px
fig = px.histogram(coco_annotations, x="label")
fig.show()
Find outliers and duplicates for specific classes
Similarity Clusters
First we visualize the general lists of duplicates and outliers, by default it is sorted by the number of elements:
fd.vis.component_gallery()


Sorting by the largest objects
fd.vis.component_gallery(metrix='size')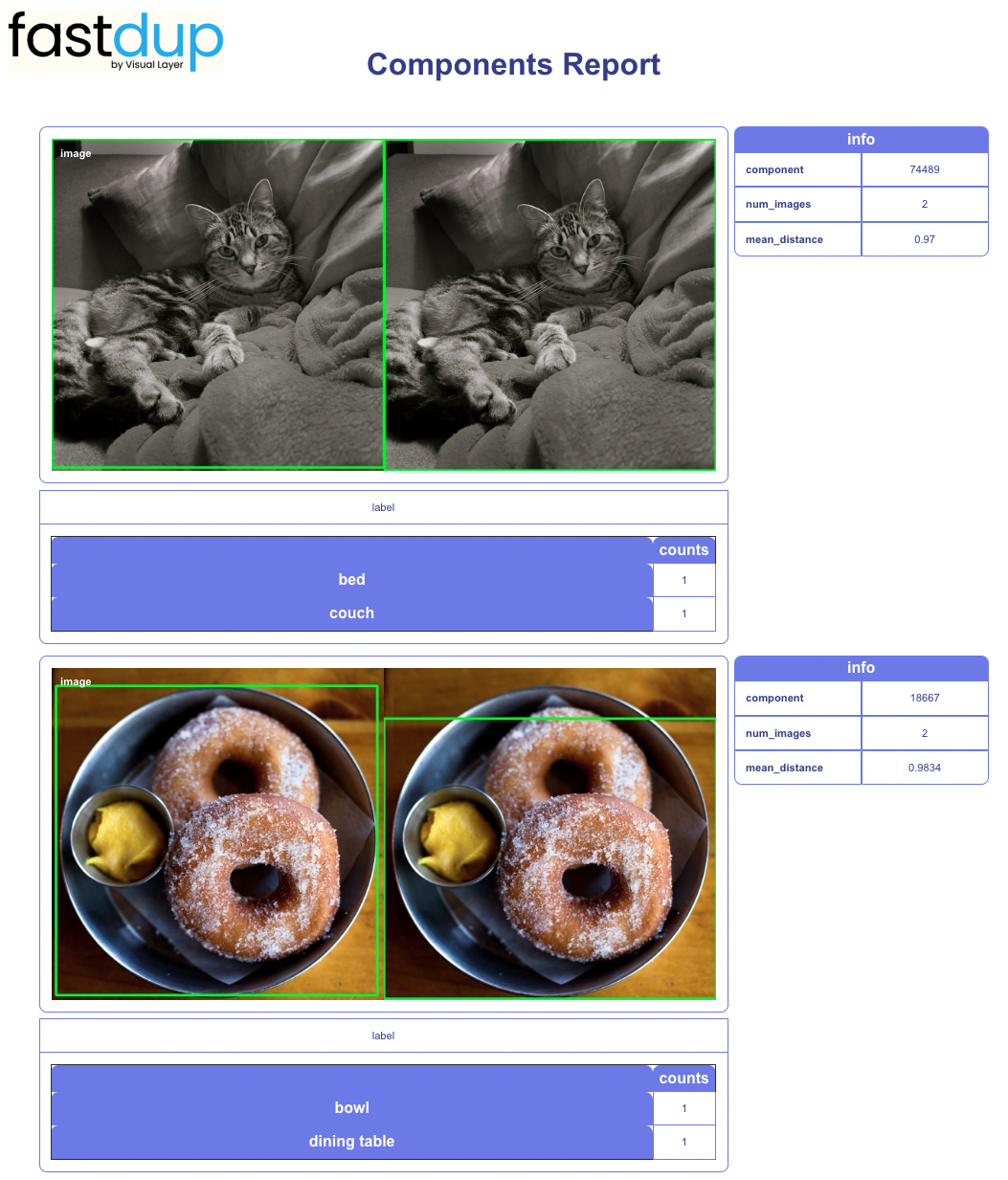
A few notable examples
Further down the gallery, a few examples of objects that might be erroneous or mislabeled.


- In the red cup image, we see individual cups in the sleeve that are barely visible get a small bounding box that captures only the lip of the cup. For many cases, this kind of annotation is not useful.
- In the cake image we can see the same object, annotated three times, each time with a different label (fork, knife and spoon) - in reality, it is very hard to tell what it actually is.
Showing galleries for a specific object class
Now we'll slice the gallery according specific classes - let's look at the 'person' class
fd.vis.component_gallery(metrix='size', slice='person', max_width=900)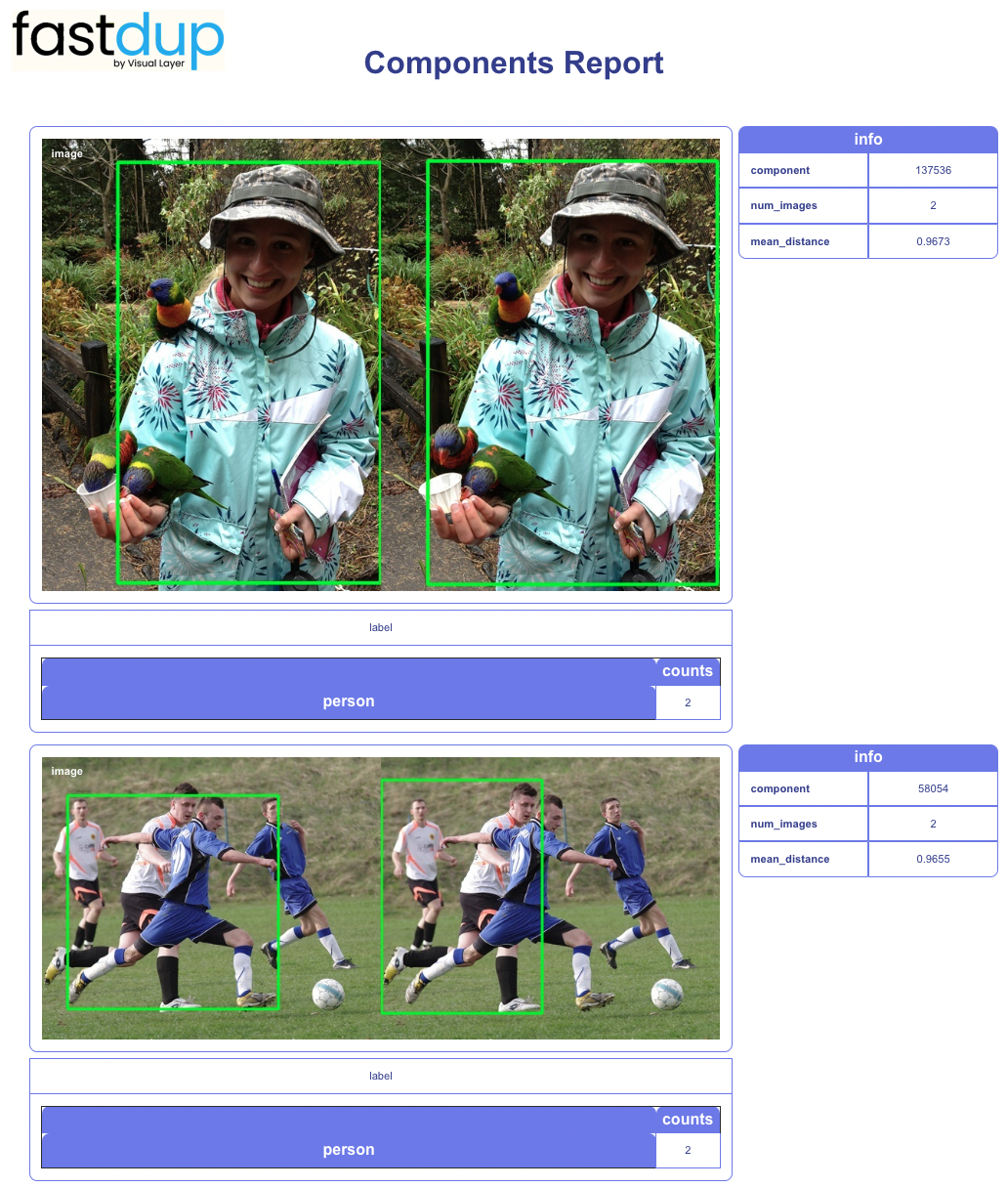
Visualizing outliers
fd.vis.outliers_gallery()

Find size and shape issues
Objects come in various shapes and sizes, and some times objects might be incorrectly labeled or too small to be useful. We will now find the smallest, narrowest and widest objects, and asses their usefulness.
df = fd.annotations()
df['area'] = df['width'] * df['height']
df['aspect'] = df['width'] / df['height']# Smallest 5% of objects:
smallest_objects = df[df['area'] < df['area'].quantile(0.05)].sort_values(by=['area'])
# 5% of extreme aspect ratios
aspect_ratio_objects = df[(df['aspect'] < df['aspect'].quantile(0.05))
|(df['aspect'] > df['aspect'].quantile(0.95))].sort_values(by=['aspect'])
smallest_objects.head(3)| img_filename | bbox_x | bbox_y | bbox_w | bbox_h | label | ext | split | fastdup_id | error_code | is_valid | area | aspect | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fd_index | |||||||||||||
| 16444 | 000000535145.jpg | 185 | 227 | 10 | 10 | apple | 0 | train | 16444 | VALID | True | 100 | 1.0 |
| 44855 | 000000553446.jpg | 332 | 229 | 10 | 10 | sports ball | 0 | train | 44855 | VALID | True | 100 | 1.0 |
| 32115 | 000000283323.jpg | 138 | 200 | 10 | 10 | car | 0 | train | 32115 | VALID | True | 100 | 1.0 |
aspect_ratio_objects.head(3)| img_filename | bbox_x | bbox_y | bbox_w | bbox_h | label | ext | split | fastdup_id | error_code | is_valid | area | aspect | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fd_index | |||||||||||||
| 134869 | 000000093298.jpg | 230 | 1 | 16 | 419 | kite | 0 | train | 134869 | VALID | True | 6704 | 0.038186 |
| 3642 | 000000002444.jpg | 1 | 136 | 11 | 263 | person | 0 | train | 3642 | VALID | True | 2893 | 0.041825 |
| 164218 | 000000116502.jpg | 222 | 63 | 16 | 318 | spoon | 0 | train | 164218 | VALID | True | 5088 | 0.050314 |
aspect_ratio_objects.tail(3)| img_filename | bbox_x | bbox_y | bbox_w | bbox_h | label | ext | split | fastdup_id | error_code | is_valid | area | aspect | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fd_index | |||||||||||||
| 77844 | 000000444692.jpg | 0 | 177 | 640 | 19 | bench | 0 | train | 77844 | VALID | True | 12160 | 33.684211 |
| 77850 | 000000444692.jpg | 1 | 58 | 638 | 15 | bench | 0 | train | 77850 | VALID | True | 9570 | 42.533333 |
| 173220 | 000000516740.jpg | 17 | 197 | 601 | 13 | train | 0 | train | 173220 | VALID | True | 7813 | 46.230769 |
Look at that! The slices reveal many items that are either tiny (10x10 pixels) or have extreme aspect ratios - as extreme at 1:46 - an object 601 pixels wide by only 13 pixels high.
Objects that didn't make the cut:
Let's look at objects deemed invalid by fastdup. These are either objects that are too small to be useful in our analysis (smaller than 10px), have bouding boxes with illeagal values (negative or beyond image boundaries), or are part of images that are missing. We can tell which is which by the error_code column in our dataframe.
fd.invalid_instances().head(3)| img_filename | bbox_x | bbox_y | bbox_w | bbox_h | label | ext | split | fastdup_id | error_code | is_valid | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 000000262162.jpg | 437 | 244 | 19 | 9 | mouse | 0 | train | 16 | ERROR_BAD_BOUNDING_BOX | False |
| 1 | 000000524325.jpg | 137 | 332 | 8 | 11 | person | 0 | train | 60 | ERROR_BAD_BOUNDING_BOX | False |
| 2 | 000000524325.jpg | 177 | 294 | 5 | 11 | person | 0 | train | 65 | ERROR_BAD_BOUNDING_BOX | False |
Distribution of error codes:
A simple value_counts will tell us the distribution of the errors. We have found 18,592 (!) bounding boxes that are either too small or go beyond image boundaries. This is 10% of the data! Filtering them would both save us gruesome debugging of training errors and failures and help up provide the model with useful size objects.
fd.invalid_instances().error_code.value_counts()ERROR_BAD_BOUNDING_BOX 18592
Name: error_code, dtype: int64Find possible mislabels
The fastdup similarity search and gallery is a strong tool for finding objects that are possibly mislabeled. By finding each object's nearest neighbors and their classes, we can find objects with classes contradicting their neighbors' - a strong sign for mislabels.
Let's visualize one of the more popular classes - 'chair':
fd.vis.components_gallery(slice='diff')There are many examples in the gallery, but let's look at the first few:

In the images above we see the many mislabeled 'chair' bounding boxes. There are multiple 'person' labeled as 'chair'.
This would be a good opportunity to go over the labeling definitions for both classes, and find cases where mix-ups can occur.
A next step could be a deeper dive into all images labeled as either chair or couch, with a lower value of clustering threshold (the ccthreshold parameter in .run()).
Summary
We have shown multiple annotation issues for the mini-coco 25k image datasetFirst, we looked at the class distribution, showing that some classes contain only a few dozen objects, which are not enough for reliable results.
Then we used fastdup to run an analysis and visualize both duplicate and outlier images, sorting according to various metrics - object size, similarity cluster image count, and mean cluster similarity score, surfacing all sorts of objects that could be removed to improve results.
Afterwards, we analyzed the bounding boxes for size and aspect ratio issues, and found over 18k object bounding boxes that are too small to be useful for most cases.
Finally, for finding mis-labels we looked into the most similar images in a specific class, and uncovered a common mixup between chair and couch classes. This is just a taste of fastdup label capabilities, which will be covered in further tutorials.
Looking for finding mislabels at scale? Sign up for fastdup enterprise.
Updated 6 months ago